
Machine Learning: tests and production
“Creating reliable, production-level machine learning systems brings on a host of concerns not found in small toy examples or even large offline research experiments. Testing and monitoring are key considerations for ensuring the production-readiness of an ML system, and for reducing technical debt of ML systems.” - The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction
I recently read the excellent book written by Emmanuel Ameisen: Building Machine Learning Powered Applications Going from Idea to Product
I definitely recommend the book to people involved at any stage in the process of developing and implementing products that use Machine Learning.
The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction
A good reference I found in chapter 6 of the book entitled: Debug your ML problems, was the article written by Google engineers: The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction
In the article, the authors:
“(…) present 28 specific tests and monitoring needs, drawn from experience with a wide range of production ML systems to help quantify these issues and present an easy to follow road-map to improve production readiness and pay down ML technical debt.”
As a good practice presented by Ameisen in his book when referring to reproducing successful results from the past: “Stand on the shoulders of giants”, I believe that we can learn from Google’s experience in building applications using Machine Learning.
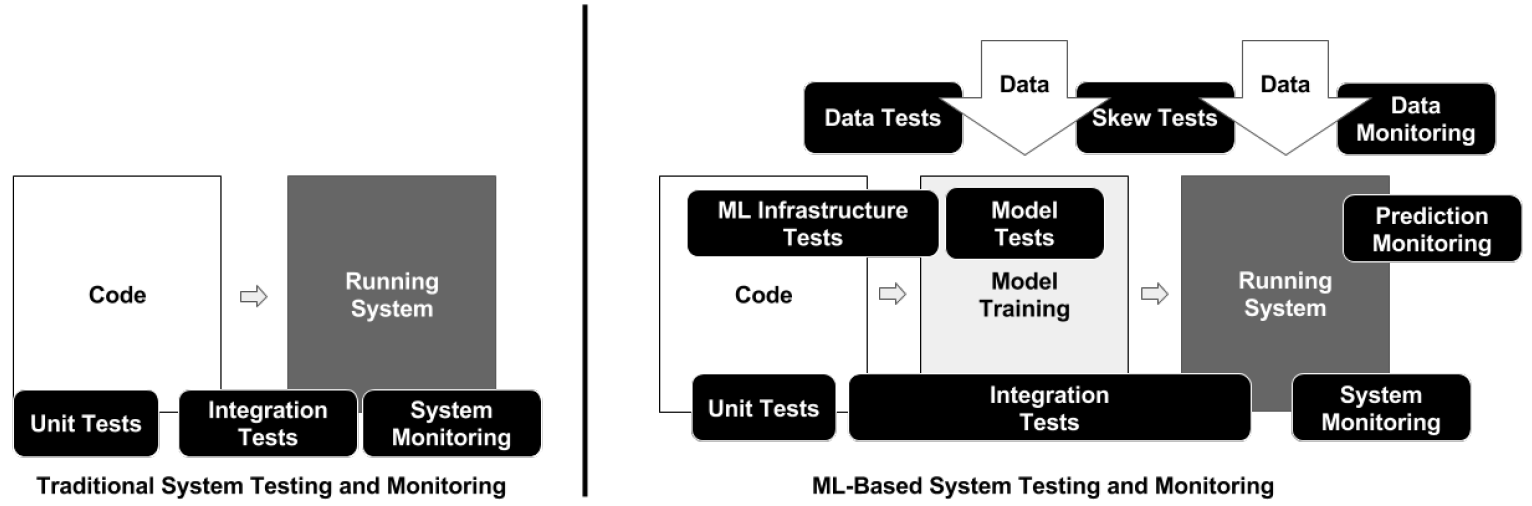
Manually coded systems vs. ML-based systems

Unlike manually coded systems, the behavior of machine learning systems depends on data and models that are not always possible to specify fully a priori
“(…) training data needs testing like code, and a trained ML model needs production practices like a binary does, such as debuggability, rollbacks and monitoring”
Tests
Data

Model

Infrastructure

Monitoring

Computing an ML Test Score

Insights from applying the rubric to real systems
- Checklists are helpful even for expert teams
- Data dependencies can lead to outsourcing responsibility for fully understanding it
- The importance of frameworks: pipeline platforms may allow building generic integration tests
Conclusion
Deploying a machine learning system with monitoring is a very complex task. This is a problem faced by virtually all players in the market who are starting their journey with data.
A good first step on this journey is to organize your data pipeline and use managed environments in the cloud for the ML tasks:
- Amazon SageMaker
- Google Cloud AI Platform
- Azure Machine Learning Studio
- Databricks
Even if we do not face the scale of some problems mentioned in the article, it is worth reflecting on how we can improve what we do today to reduce technical debt in the future.
Further reading
- The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction
- Building Machine Learning Powered Applications Going from Idea to Product - Emmanuel Ameisen
- ML in Production blog
- What is your machine learning test score?
- MLflow: A Machine Learning Lifecycle Platform
- Databricks for Machine Learning